Let's recap what we've covered so far: We know that there are different types of exchanges, and they dispatch messages to queues based on set rules. Messages and queues can be configured to be durable, and we can control whether they should be deleted from the queue. Also, messages can be equipped with arbitrary header and meta data. Using those techniques, we could implement some sort of replacement for full-featured worker queues ourselves, including automatic setup of the needed Bunny connections, channels and exchanges. We would also need a bunch of helper methods, such as methods that reassemble Sidekiq's perform_async method for enqueuing jobs. Eventually we would end up extracting all the boilerplate into a standalone gem that handles all Bunny configuration and communication with RabbitMQ. Wouldn't it be nice to have all those things already set up?
Enter Sneakers.io.
In a nutshell, Sneakers.io introduces worker classes that include the Sneakers::Worker module. The now available work(message) method is our anticipated replacement for perform_async, and all the configuration regarding Bunny's connections and channels can be given globally or on a per-worker basis. So, how exactly is Sneakers.io integrated in the sample Rails application?
Test driving Sneakers.io
The Sneakers.io wiki gives some first hints regarding setup, and integrating Sneakers.io in a Rails application involves just a few steps more. My 'rabbitmq_showcase' sample Rails app uses mostly the example configuration, and adds a few tweaks to make Sneakers.io behave more pratical during development:
Sneakers.configure heartbeat: 2000,
amqp: "amqp://ubuntu:ubuntu@192.168.0.12:5672",
vhost: "test",
metrics: Sneakers::Metrics::LoggingMetrics.new,
daemonize: false,
heartbeat_interval: 2000,
start_worker_delay: 0.2,
durable: true,
ack: true,
workers: 5,
retry_timeout: 30000,
retry_max_times: 3,
timeout_job_after: 60,
threads: 4,
prefetch: 4,
log: STDOUT
Sneakers.logger.level = Logger::INFO
After all my explanations of ack, prefetch and durablity most of the configuration options should make sense ;) All other set options deal with the message broker's connection settings, settings for Sneakers.io, concurrency and logging (and are well-explained in above linked wiki). But what value does Sneakers.io precisely add to the application? The answer is simple: Automatic re-enqueuing and job workflows.
Worker classes and workflows
Let's take a look at the lengthy explanation on the "Workflow" tab in the 'RabbitMQTestdriver' Java program:
What exactly do I mean by that?
Say you want to make sure some sort of processing step is only executed after another step has finished. A very practical use case would be that a file is generated in one background worker step and in the second step the file should be sent via e-mail or being uploaded somewhere. Of course the second step does only make sense if the first one succeeds, in other words they are interdependent. The way RabbitMQ handles such scenarios is with queues and messages (naturally). Messages in this context are like start signals for workers, and in our case we would have two workers that listen to their respective queues if they should start running. And this is where Sneakers.io comes in handy. This is a worker class that would reflect step one in this scenario:
class StepOneWorker
include Sneakers::Worker
from_queue "generate_pdf"
def work(format)
unless(file_name = GeneratePDF.call(format))
return reject!
end
publish(file_name.to_s, to_queue: "upload_file", persistence: true)
logger.info("Published to step 2: 'upload_file'")
ack!
end
end
Remember in the last blog post how we declared the worker queue, did set up its durablity and whether it should acknowledge messages? All taken care of by these few lines of worker-DSL and configuration.
Now the benefits of Sneakers.io become clear as daylight: Together with above configuration it automatically sets up the connections, exchanges and queues to make the whole application respond to messages that are inserted into the 'generate_pdf' queue. It uses the renowned ack! and reject! semantics to indicate success and failure, and that is exactly how we control whether a job should be forwareded to step 2 of the workflow (by sending just another message to a queue). But what if the PDF generation fails for some reason and we don't acknowledge the message?
RabbitMQ extensions
Here they come, the last pieces of the puzzle. When we look at a real worker configuration from the sample Rails app, we notice that there is some more stuff going on:
from_queue "workflow_in",
handler: Sneakers::Handlers::Maxretry,
arguments: { :"x-dead-letter-exchange" => "workflow_in-retry" }
First off, we use the arguments parameter to pass a hash to the queue options. The arguments parameter is one of the optional parameters that control the behaviour of the queue, like durable. As explained in the Bunny documentation for queues, the arguments parameter is "typically used by RabbitMQ extensions and plugins". Another hint is the "x-" key of the hash, it does have an odd format, does it? This indicates that we are using one of RabbitMQ's eXtensions named 'dead-letter-exchange'. RabbitMQ's docs about dead letter exchanges are quite thorough, so long story short: We specify that rejected messages should be routed by the exchange with the name "workflow_in-retry". The second thing we do is specifying a message handler class. As written on Sneakers.io's wiki page about message handlers, handler classes deal with failed messages. Let's take a look at the used message handler.
Message handlers
Retries
The message handler used in the sample Rails application is a customized version of the one coming with the Sneakers.io source code. I won't explain the code line by line, here's just the gist of it:
It declares 3 dead-letter-exchanges based on the name of the queue. Following the code example above, the generated exchanges would be 'workflow_in-retry', 'workflow_in-error' and 'workflow_in-retry-requeue'. The generated exchanges are of type "topic" and durable, like the auto-generated main "sneakers" exchange:
retry_name = "#{@worker_queue_name}-retry"
error_name = "#{@worker_queue_name}-error"
requeue_name = "#{@worker_queue_name}-retry-requeue"
@retry_exchange, @error_exchange, @requeue_exchange =
[retry_name, error_name, requeue_name].map do |name|
@channel.exchange(name, type: "topic", durable: opts[:durable])
end
Like illustrated in above linked RabbitMQ docs about dead letter exchanges, we can configure queues to use a specific dead letter exchange. The simplest case is the setting for the error-queue:
@error_queue = @channel.queue(error_name, durable: opts[:durable])
@error_queue.bind(@error_exchange, routing_key: "#")
The given routing key is configures that each of the queues should subsribe to all messages sent to it. This will work since the three queues are used by just this message handler class. The main worker queue is simply bound to the re-enqueuing exchange:
queue.bind(@requeue_exchange, routing_key: "#")
A cool trick is to configure the 'retry_queue' to use the re-enqueuing exchange as dead letter exchange for itself. At last we bind it to the 'retry_exchange':
@retry_queue =
@channel.queue(retry_name, :durable => opts[:durable],
:arguments => {
:'x-dead-letter-exchange' => requeue_name,
:'x-message-ttl' => @opts[:retry_timeout]
})
@retry_queue.bind(@retry_exchange, routing_key: "#")
Now that we have all needed queues and exchanges configured, there appears another unfamiliar option: "x-message-ttl". By the name of the key we can assume that it's concerning another extension we'll have to look at.
Delayed execution of messages
"ttl" in the second argument key stands for "time to live". RabbitMQ itself does not support mechanisms to tell consumers or messages that they have to wait for a period of time before they get consumed (like the run_at: parameter provided by delayed_job, for instance). However, we can configure queues on how long they should keep messages enqueued before they are declared "dead". And this is exactly what we are doing in above setting. We implement deferred execution of messages by using AMQP constructs and extensions: moving messages between queues when a certain time period has expired, controlled by the retry_timeout option from the Sneakers.io configuration above. See how all the pieces fit nicely together?
All the remaining code in the retry handler is about counting retries and moving the messages back and forth between the three ('-retry', '-retry-requeue' and '-error') queues. The maximum number of retries is given in above shown global Sneakers.io configuration.
Sending messages to Sneakers.io
Another nice thing about Sneakers.io is that on the outside everything just stays the same. The method in the Java code to send messages to be processed by Sneakers.io is exactly the same as it was before:
channel.basicPublish("sneakers", "workflow_in",
new AMQP.BasicProperties.Builder()
.contentType("text/plain").deliveryMode(2)
.build(),
message.getBytes());
No surprises here. We just use the automatically set up "sneakers" exchange and the name of the queue which will trigger the correct worker for us - easy.
The whole picture
Now you should fully understand the example in my little applications. If you try them out, you are able to see all the mentioned constructs at work. When you start Sneakers.io as indicated in above linked docs (as rake task with the worker classes set trough ENV), it will set up all needed main/retry/requeue/error exchanges and queues automatically:
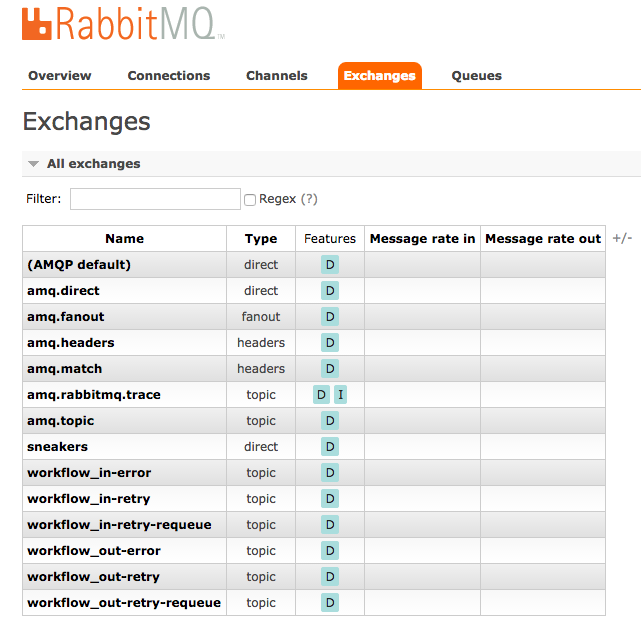
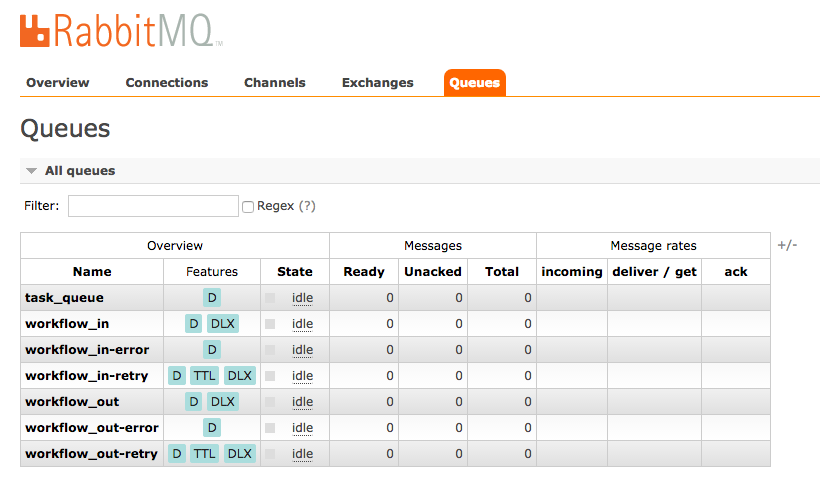
The abbreviations DLX and TTL in the "features" column in the screenshot above should make sense by now. If you test-drive the "workflow" functionality and flood the broker with a couple of dozen messages, sooner or later something like this will happen: The processing of a message in the first step will fail. It gets enqueued in the 'workflow_in-retry' queue, and since we configured the queues and exchanges like above it will remain enqueued for 30 seconds, then be moved back for another attempt to be consumed. It will remain in this loop until either the "retry_max_times" value is reached and it ends up in the "workflow_in-error"-queue or it will finally present itself on the website like on the screenshot below.
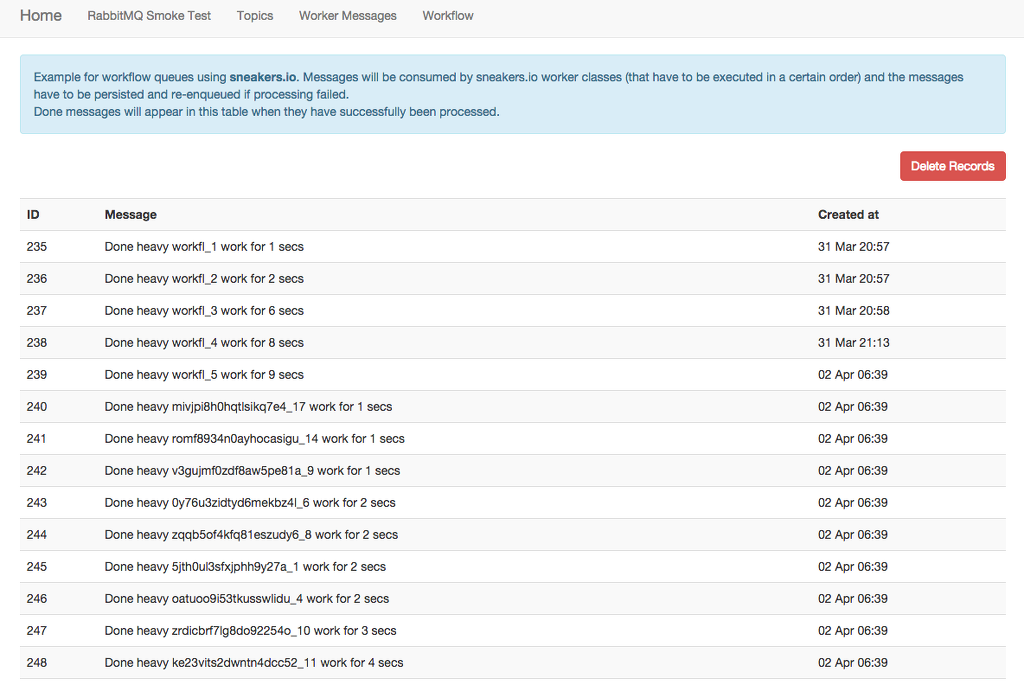
Remember in part 1 of this blog post series when I suggested to enable RabbitMQ's "shovel" plugin? That's because in our current setup, if the message-processing fails three times in a row, messages will eventually be inserted into the 'workflow_in-error' queue and pile up in there. In a real world scenario you would fix the error that has caused the failure, and after you made sure the messages can be processed safely again, you are able get them back into the retry-loop by using the "shovel" functionality by moving messages between queues. We would use the "shovel" functionality to re-enque the messages into the 'workflow_in-retry' queue manually.
Conclusion
And that was the last piece of the puzzle. We've covered all the necessary bits and pieces to achieve all anticipated features of failsafe worker-queues: Easy setup, a nice DSL for adding background workers, message and queue persistence, load balancing, deferred execution of messages, automatic retries, and all that on top of RabbitMQ!
By using Sneakers.io you'll get some ease of setup and a worker DSL for free. Under the hood it just uses Bunny, and for the written sample applications I only used a small subset of what's possible with RabbitMQ. More things to discover include: queue-exclusive consumers, explicit delivery handlers, consumer tags, other methods on queues like Queue#pop, Queue#stats etc., exchange callbacks, "headers" exchanges and "x-match-header"-rules, other "x-" arguments like "x-death", other methods on exchanges like Exchange#delete, declaring messages as mandatory, prioritized messages... I could go on.
I hope my journey has been just a little bit entertaining and helpful to accustom yourself to the overwhelming world of RabbitMQ and Rails ;)